13 minutes
The Fellowship of the Optim: How I met my thesis
Nếu như đã đọc bài viết trước, các bạn sẽ biết mình đang làm thesis về đề tài Video Super Resolution. Thật ra đề tài này không phải là dự định ban đầu của mình, đúng hơn, mình còn chưa bao giờ nghĩ đến đề tài này cho đến khi gặp thầy hướng dẫn. Trong bài viết này, mình sẽ kể lại mình đã bắt đầu với thesis của mình như thế nào, và tình hình hiện tại của nó.
Mình lên ý tưởng (không hẳn) cho thesis của mình như thế nào?
Mình khá hoang mang với việc làm thesis, và việc nghĩ đến nó thôi cũng làm mình lo lắng. Mặc dù mình đã có một ít kinh nghiệm về việc làm nghiên cứu, nhưng thẳng thắn mà nói thì mình chưa có một “công trình” hoàn chỉnh nào cả. Dự án ở môn Nghiên cứu khoa học thì không có kết quả đáng kể nào cả, còn dự án mình làm ở AI Lab thì vẫn chưa hoàn thành lúc mình quyết định xin nghỉ. Lúc đó, mình không định hình được mình sẽ cần phải làm gì có thể tạo nên một công trình nghiên cứu thành công cả. À thật ra về mặt lý thuyết thì mình biết, nhưng mình không biết phải làm mọi thứ như thế nào. Mình biết làm thesis chắc chắn sẽ là không phải là một con đường dễ dàng cho mình, nhưng trong những lựa chọn mình có, thì nó vẫn là lựa chọn mà mình cảm thấy tự tin nhất. Challenge accepted, bắt tay vào làm thôi.
Những việc đầu tiên mình cần làm đó là tìm đề tài, tìm người làm thesis chung, và tìm người hướng dẫn. Lúc lên ý tưởng cho thesis, mình vẫn còn đang làm ở CinnamonAI và tập trung vào những bài toán liên quan đến Graph Neural Network (mình sẽ gọi tắt là GNN). Với việc đang là một chủ đề khá mới và hấp dẫn, mình nghĩ làm thesis về Graph Neural Network sẽ là một lựa chọn hợp lí. Nhưng tìm kiếm bài toán vốn không phải là điểm mạnh của mình. “Làm về Graph Neural Network, nhưng làm gì bây giờ?” - đây là câu hỏi mà mình luôn trăn trở trong suốt một thời gian dài. Mình suy nghĩ về một số hướng mình có thể làm, nhưng cảm thấy đều bế tắc cả. Đề xuất một network architecture mới - mình chỉ nghĩ được đến việc áp dụng những architecture đã hoạt động hiệu quả trong những bài toán về Vision hay Natural Lanuage vào Graph, nhưng hầu như những sự kết hợp đó đều được được thực hiện. Mình cũng nhận thấy một vấn đề nho nhỏ là những dataset được dùng trong các papers về GNN rất là nhỏ, đặc biệt so với kích thước của model, nên mình nghĩ tìm cách đưa ra một dataset mới (kiểu như ImageNet) sẽ là một đóng góp đáng kể. Nhưng mình nghĩ, đó không phải là một hướng đi khả thi đối với mình. Mãi một thời gian sau, mình cũng vẫn loay hoay trong những suy nghĩ rối bời này. Lúc đó, nếu ai hỏi, thì mình cũng sẽ luôn chỉ trả lời là mình sẽ làm về GNN và không nói thêm được gì nữa.
Vì không muốn áp lực lên bản thân quá nhiều, cộng với việc mình vẫn phải tập trung vào một số môn học ở trường, mình thường xuyên trì hoãn về việc tìm kiếm ý tưởng cho thesis. Lúc này, mình quyết định chuyển hướng qua việc đi tìm bạn làm chung vì dù sao hai người động não suy nghĩ thường sẽ tốt hơn một người, nhất là một người đang bế tắc :))). Mình bắt đầu đi rủ những đứa bạn mà mình nghĩ sẽ có thể hứng thú về Deep Learning để làm chung thesis. Và sau đó, sao nhỉ, là một chuỗi những lời từ chối khi những người mình hỏi nếu không phải đã quyết định làm một mình, thì cũng đã có nhóm sẵn rồi. Lúc đó, mình cảm giác như mình đang là một diễn viên hài trong một bộ phim và khán giả đang cười vào tình huống trớ trêu này của mình.
Mình tạm gác hai việc tìm người làm chung và tìm ý tưởng qua một bên, và bắt đầu đi liên hệ với những thầy cô mình biết để tìm giáo viên hướng dẫn. Mình lên hệ thầy Triết, nói về việc mình đang dự định làm về Graph Neural Network, và hỏi thầy có biết những thầy cô nào có thể giúp mình trong đề tài này không. Vì mình cũng chưa có bài toán cụ thể, nên thầy cũng không giúp gì được cho mình nhiều. Thầy khuyên mình cứ suy nghĩ thêm, khi nào có hướng đi cụ thể thì thầy sẽ giúp được và động viên mình. Mình không biết thầy có cảm nhận được tinh thần đang chạm đáy của mình lúc đó qua những tin nhắn bình thường hay không, nhưng những lời động viên của thầy giống như những tia sáng lé loi duy nhất mà mình cảm nhận được trong suốt khoảng thời gian đó. Và đúng là sau những lời động viên thì mọi chuyện của mình bắt đầu trở lại đúng quỹ đạo thật.
Một đứa bạn khác của mình (mà mình không nghĩ là sẽ làm thesis về Deep Learning) có nhắn hỏi về việc mình đã có nhóm chung với ai chưa. Và thế là mình đã tìm được người làm chung theo cái cách mà mình không ngờ nhất =))). Tiếp theo, mình liên hệ với thầy Sơn - người dạy mình 2 môn Computer Graphics và Computer Vision - để hỏi về việc hướng dẫn luận văn. Sau khi nghe mình chia sẻ về việc đang cảm thấy bế tắc trong việc tìm kiếm đề tài, thầy đã đề xuất cho mình một số đề tài. Sau một thời gian suy nghĩ và bàn bạc với bạn mình, mình đã quyết định chọn chủ đề về Video Super Resolution (một trong những chủ đề mà thầy mình đề xuất). Và thế là đề tài của mình ra đời. Nhìn lại, có lẽ vấn đề của mình không phải là việc tìm ra bài toán, vì lúc mình chọn Video Super Resolution mình cũng đã nghĩ ra được hướng đi nào đâu, mà là tìm một người có thể dẫn dắt mình, giúp mình có thể tự tin với lựa chọn dù chưa biết phía trước điều gì đang chờ đón.
Mình bắt đầu như thế nào ?
Vừa rồi là phần hồi tưởng của mình về quá khứ, phần tiếp theo sẽ về hiện tai và mình nghĩ sẽ một số điều thú vị mà các bạn có thể thu về được cho mình. (thật ra nó cũng là quá khứ nhưng vẫn tiếp tục trong hiện tại - kiểu như thì hiện tại hoàn thành trong tiếng Anh vậy :)) ). Mình hiểu Super Resolution là làm gì (mình nghĩ đa phần mọi người cũng sẽ hiểu) nhưng mình chưa tìm hiểu sâu về đề tài này. Trong những course Deep Learning mà mình học, mình nhớ cũng không có course nào sử dụng bài toán này làm ví dụ (nếu các bạn biết có course nào thì có thể comment để mình cập nhật lại nhé, vì lâu rồi mình cũng không tìm những course Deep Learning mới). Vì vậy, mình quyết định bằng cách đơn giản nhất là … đọc paper :)). Và đây là cách mình tìm kiếm papers và những công cụ mình sử dụng kèm theo để tổng hợp kiến thức.
Để tìm papers thì mình sẽ sử dụng Google Scholar, Connected Papers và Paperswithcode. Google Scholar để mình có thể tìm paper chính xác hơn, thay vì chỉ search bằng Google thông thường. Connected Papers để tìm những papers liên quan đến một papers nào đó và Paperswithcode giúp mình tìm những papers đang là “state-of-the-art” và nhanh chóng biết được papers đó có code sẵn không. Mình sẽ lấy một ví dụ cho các bạn dễ hiểu.
- Đầu tiên, mình sẽ thử search Google Scholar với từ khóa “Video Super Resolution”. Mình thường sẽ chọn những papers gần đây hoặc có số citation cao để bắt đầu. Mình chọn paper Video super-resolution with convolutional neural networks.
- Tiếp theo, mình có thể sử dụng Connected Papers để tìm những papers liên quan đến papers này.
- Mình sẽ dùng thêm Paperswithcode để tìm, qua đó sẽ biết thêm được những dataset đang được sử dụng cho bài toán này và các phương pháp hiện nay đang có kết quả như thế nào.
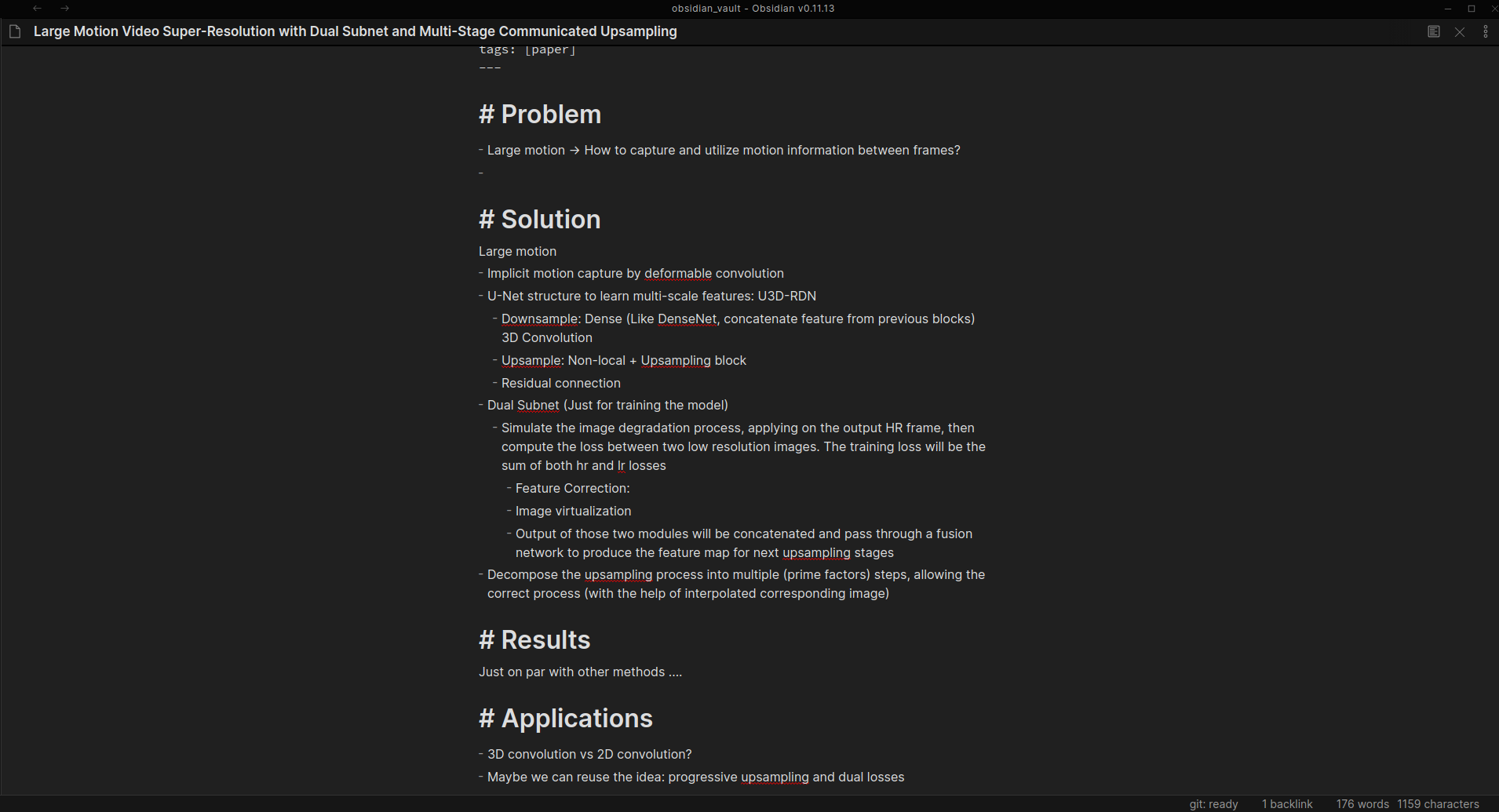
Sau khi tìm xong thì mình bắt đầu đọc paper thôi. Về cách đọc paper thì đã có rất nhiều hướng dẫn chi tiết và cách mình đọc paper thì cũng không có gì khác biệt lắm. Mình thường đọc và sử dụng Obsidian.md để take notes lại. Mình thường take note theo 4 câu hỏi chính: “Bài toán ở đây là gì?”, “Phương án giải quyết nó như thế nào?”, “Kết quả ra sao?”, “Mình có thể tái sử dụng hay mở rộng ý tưởng ở đây như thế nào?”. Mình khá thích Obsidian.md là mình có thể link những note lại với nhau và tạo thành một cái knowledge graph. Công cụ này giúp mình kết nối những papers lại với nhau dễ dàng hơn một tí (vẫn tốn công sức ban đầu, nhưng sau này nếu các bạn có xem lại thì sẽ dễ có được góc nhìn tổng quan hơn).
Ngoài phần papers ra thì một phần quan trọng không kém đó là code. Trong lúc tìm paper, mình cũng thường ưu tiên những papers có code (chính chủ hoặc re-implementation đều được, bạn có thể dùng Paperswithcode để tìm). Mình sẽ cần phải implement và thử nghiệm khá nhiều phương pháp, nên mình cần những codebase thuận tiện cho việc mở rộng. Thuận tiện ở đây mang ý nghĩa: mình cần có tốn nhiều công sức để thêm một architecture hoàn toàn mới không; những utility functions như training, evaluation có tái sử dụng được không, … (Vì mình lười nên tự implement luôn là phương án cuối cùng của mình :)) ). Cuối cùng, mình quyết định lựa chọn MMEditing vì nó đáp ứng được khá nhiều tiêu chí ở trên, thiết kế khá đơn giản, và cũng đang được maintained. Mình không giỏi về code lắm, nên mình dành khá nhiều thời gian để tìm hiểu và học về repo này. Cách mình học thì cũng không có gì đặc biệt lắm, cứ chạy code, chèn cái snippet này vào __import__('ipdb').set_trace() và chạy từng dòng để hiểu mọi thứ hoạt động như thế nào =)))) (Nó hiệu quả hơn print("What the heck?") nhiều đấy, các bạn cứ thử xem :)) ).
Thesis đến đâu rồi :'( ?
Trong giai đoạn này (sau khi kết thúc kì 1 năm 4, khoảng từ tháng 1/2021) mình cũng khá là trì hoãn trong việc làm thesis. Sau đây là một số lí do biện hộ cho việc mình trì hoãn =))):
- Mình làm full-time nên ban ngày mình sẽ tập trung hoàn toàn vào những bài toán ở công ty, thời gian còn lại thì mình muốn nghỉ ngơi. Ngoài ra, thỉnh thoảng mình cũng thích làm công việc của công ty hơn là làm thesis :))
- Mình cần hoàn thành thesis proposal. Do vậy mình dành thời gian chủ yếu để đọc papers và trì hoãn việc code lại. Hậu quả là sau khi hoàn thành proposal thì mình chưa thật sự chạy thử một model nào cả.
- Codebase
MMEditingkhá lớn, mình không biết nên bắt đầu từ đâu.
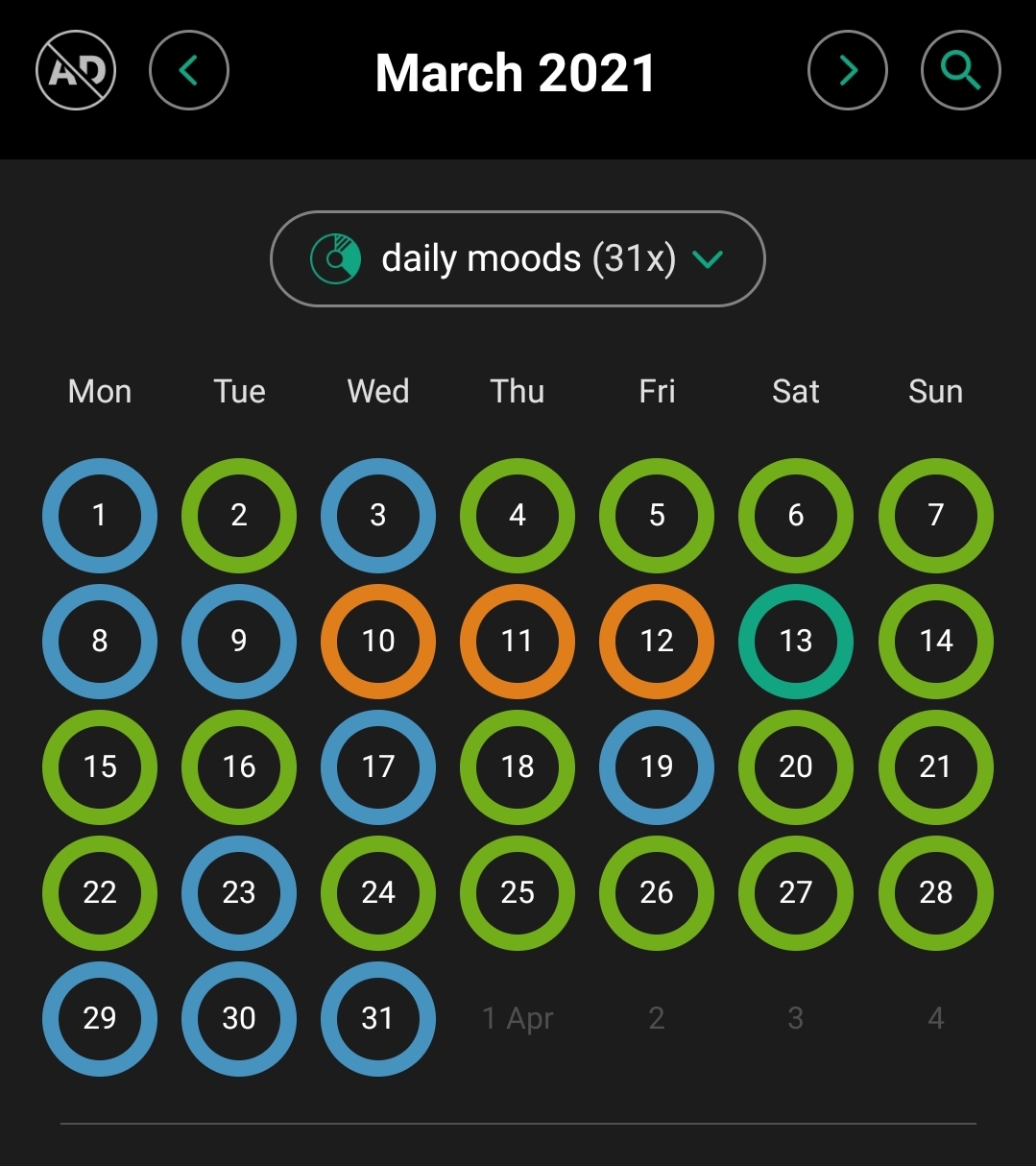
Trong thời gian này mình còn nhận ra được một bài học khá thú vị. Mình đọc ở đâu đó lời khuyên là bạn nên làm 2 projects cùng một lúc, để nếu có một cái bế tắc thì bạn sẽ cảm thấy mình productive khi làm cái còn lại. Mình thấy lời khuyên này khá đúng, nhưng chỉ là, mình lại gặp bế tắc ở cả 2 projects (công ty và thesis) cùng một lúc. Kết cục là mình cảm giác như một thằng phế vậy =)) (Nếu các bạn muốn nghe về chuyện projects ở công ty thì cứ comment nhé, mình sẽ kể ở một bài khác, nó cũng là một bài học đau thương cho mình). Đây là biểu đồ tâm trạng mỗi ngày của mình trong thời gian đó (màu xanh lá cây là ổn, màu xanh nhạt là không ổn, màu cam là tệ).
Một bài học nữa (mình nghĩ chắc các bạn cũng nghe nhiều rồi) mà mình rút ra được là không nên để những nỗi sợ ban đầu làm bạn chùn bước. Mình đã lo sợ trước thesis proposal, cảm thấy hoang mang giữa một codebase mà mình nghĩ chắc mình sẽ không hiểu được. Nhưng từng bước một, mình dần dần vượt qua được những chướng ngại đó. Đây là bài học của một người bình thường (mình nghĩ đúng hơn là hơi “phế”) nên mình nghĩ có thể nó sẽ dễ đồng cảm với các bạn hơn một người thành công :)).
Tóm lại, về thesis, hiện tại thì mình đã hoàn thành xong thesis proposal, đã hiểu code MMEditing, implement xong một baseline model và đang train để xem kết quả như thế nào =))). Đây là giai đoạn mình thích nhất: được thử nghiệm nhiều ý tưởng và cầu nguyện mỗi lần train model =))))
Bài viết hôm nay sẽ hơi dài một tí, vì mình dự định sẽ viết mỗi tuần 1 bài (chắc là vào cuối tuần). Nếu mình rảnh thì mình có thể viết nhiều hơn, nhưng mình không hứa chắc được, phải làm mới có thứ mà chia sẻ chứ :))). Những bài viết sau mình sẽ viết cụ thể mình đang làm gì, vấn đề mình gặp phải và mình giải quyết nó như thế nào. Đưới đây là một ví dụ (mà mình mới giải quyết xong hôm nay).
Khi mình evalute kết quả Super Resolution bằng việc sử dụng thuật toán cực kì đơn giản là resize bằng bicubic interpolation, kết quả PSNR (Peak Signal to Noise Ratio) của mình khá là cao, khoảng 31 db, trong khi số liệu trong các papers cũng chỉ ở khoảng 26 db. Mình bắt đầu kiểm tra lại mọi thứ:
- Code evaluation đã chính xác. Mình dùng hàm có sẵn trong
MMEditingnên xác suất sai là khá thấp. Mình kiểm tra thêm trong phần issues của repo thử xem có cái nào liên quan đến PSNR luôn không cho chắc. - Mình evaluate thêm kết quả của model hiện tại mình đang train, ra được PSNR khoảng 33 db, cao hơn khá nhiều so với model trong một số papers trong khi model của mình cũng chỉ là baseline. Lúc này mình bắt đầu nghĩ là có thể nằm ở data.
- Mình visualize kết quả High Resolution và thấy kết quả cũng không quá tốt, và đạt PSNR cao như vậy thì rõ ràng là có vấn đề.
- Mình kiểm tra thêm metric khác là SSIM (Structural Similarity Index Measure) và thấy kết quả của metrics này khá tương đồng với các papers, điều này có nghĩa là cách mình dùng PSNR có vấn đề.
- Mình nhớ lại là một số papers evaluate PSNR trên Y channel trong định dạng YCbCr thay vì RGB như thông thường. Mình implement hàm để covert ảnh sang YCbCr và thử lại. Kết quả ra đúng như mình mong đợi -> Problem solve :))).
À còn một điều nữa mà mình cần làm, là tìm hiểu về định dạng màu YCbCr và tại sao PSNR lại không hoạt động tốt với định dạng RGB. Mình sẽ chia sẻ sau khi mình hiểu nhé :">.
Các bạn có thể tìm đọc tất cả bài viết của series này tại đây.