3 minutes
Efficient Sub-pixel Convolution
The efficient sub-pixel convolution is proposed in 1 and explained in details in 2. Since it was introduced, the method has quickly becam the most popular choice for upsampling layer in Super Resolution networks. IMHO, the explanation in 2 is very difficult to follow because the way sub-pixel convolution (or Transpose Convolution) is performed in that paper is very confusing.
In short, the efficient sub-pixel convolution is just a more efficient way to do sub-pixel convolution. Its superiority lies in the efficiency, not the upsampling quality.
In order to understand how this works, you need to have basic understanding of Transposed convolution. We will use an example of upsampling a \(4\times 4\) feature map to a \(8\times 8\) to see the equivalence between the normal transposed convolution and the efficient sub-pixel convolution and how the latter method is more efficient.
Considering a normal convolution with kernel size \(k = 4\), stride \(s = 2\) (stride \(2\) because we want to double the spatial size of the feature map) and padding \(1\). Applying this convolution on a \(8 \times 8\) input results in a \(4 \times 4\) output feature map. Its corresponding transposed convolution has kernel size \(k' = 4\), stride \(s' = 1\) with padding \(p' = 2\) (The formulation of transposed convolution’s output size can be found in 3), producing \(8 \times 8\) from \(4 \times 4\) input.
Since the stride \(s = 2\), in addition to padding values around the transposed convolution input, \(s - 1\) zero pixels are added between actual pixels. The transposed convolution’s input, after inserting zeros, is: (Green circles are actual pixels, blue are zero padding)

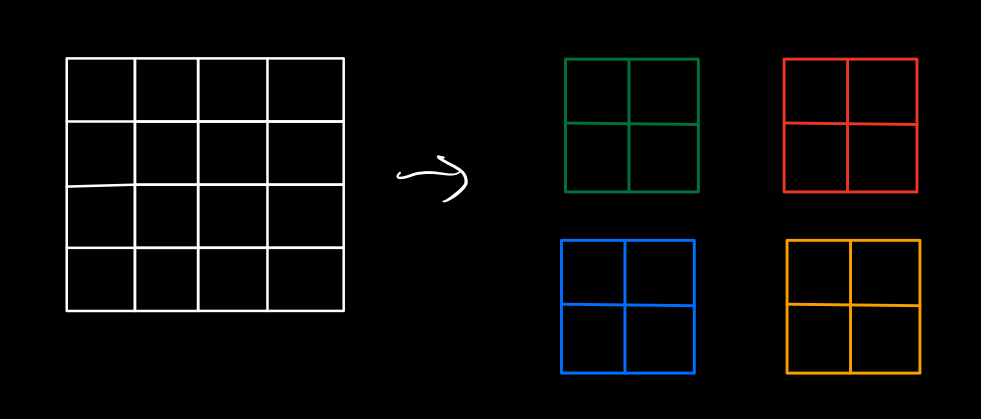
Now we use a \(4 \times 4\) kernel and slide on this feature map to perform convolution. While doing that, noticing the set of weighs in the kernel that are activated at the same time, you can see the pattern. Weights at position at having the same number will be activated - multiplying with actual pixels - at the same time (For some position at the corner of the feature map, it’s possible that only 2 of 4 weight position are activated but it doesn’t affect the generalization). While those weights are activated, weights at other position in the kernel receive zero values.
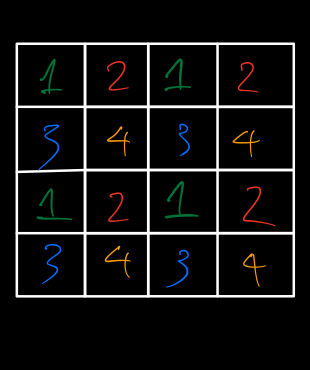
This observation suggests that it’s possible to break down the \(4 \times 4\) kernel into four \(2 \times 2\) kernel using the observed pattern. The transposed convolution, therefore, is equivalent to apply four \(2 \times 2\) convolution on the initial feature map (without zero values inserted between actual pixels), followed by rearranging pixels in result feature maps to create the \(8 \times 8\) output. This is exactly what the efficient sub-pixel convolution does. The efficiency comes from doing the convolution with feature map with smaller spatial size and avoiding inserting zeros between pixels.